
Kaggle Dataset ”Corn, Oat, Cereals & Grains Futures Data"のEDAと機械学習モデル_01
カテゴリー: データサイエンス
作成日: 2023-10-30
Kaggleは世界最大級のデータサイエンスコンペティションプラットホームです。Kaggleは企業や行政などの組織とデータサイエンティスト/機械学習エンジニアを結びつけるプラットホームとなっていて、コンペティションの他に、約20万のdatasetsとそれらdatasetの解析や機械学習モデルのプログラムcodeが投稿されています。どのようなデータが公開されているかを知ることができ、さらにデータ解析や機械学習モデル作成するためのアルゴリズムの知識を深め、そのプログラミングをトレーニングすることができます。 まずダウンロードしたデータの概要から詳細までを解析します。これを探索的データ解析:EDA(Exploratory data analysis)と言います。
Dataset "Corn, Oat, Cereals & Grains Futures Data"について
穀物の収量や価格の予測は食品原料の安定な供給に重要です。KaggleのDatasetで穀物に関して検索するといくつかのDatasetが見つかります。
今回は"Corn, Oat, Cereals & Grains Futures Data"とそのデータ解析と機械学習モデルを紹介します。このデータセットの提供者はDatesetsランク148位/104,913のDatasets Expertです。またNotebooks Expertでもあり、Kaggleで活発な活動をしています。
このデータセットは、トウモロコシ、オート麦、その他の穀物に関連する先物の包括的かつ最新のデータを提供しています。先物とは、特定の穀物を、将来の日付にあらかじめ決められた価格で、買い手が購入し、売り手が売却することを義務づける契約です。
このデータセットの使い方として以下が提示されています。
このデータセットへのアクティビティ
Usability(使いやすさ)が10と最高評価となっています。Completeness、Credibility、Compatibility の各項目の評価が100%となっていて、非常に使いやすい、信頼の高いデータセットです。
- Usability: 10
- Licence: Attribution-NonCommercial 4.0 International
- Votes(いいね): 28
- Views: 5,002
- Downloads: 857
- Notebooks(プログラムコード): 4
データファイルの構成
ダウンロードしたデータセットに含まれているall_grains_data.csv ファイルを使います。
- ファイル形式: csv
- ファイル容量: 2.1 MB
- 列数(データ項目): 8
- 行数(データ数): 35,033
今回のデータ解析手順
Pythonで作成したプログラムにて下記の手順で解析しました。
- ダウンロードしたzipファイルの解凍
- データファイルの読み込み
- 列名(項目名)と型を確認
- 列'date'を時系列データへ変換:文字列型なので時系列型へ変換
- 欠損値の有無を確認: 欠損値はありませんでした
- 基本データの可視化
- 列 'open' すなわちopen priceを目的変数として機械モデルを作成
all_grains_data.csvの構成
csvファイルを読み込んだデータフレーム(df)に関数df.info()を実行すると、下記が表示されます。8つの列と35033の行があります。列'ticker'は穀物先物市場独自の穀物の相場記号。'commodity'は穀物の種類で、'Corn'、 'Oat'、 'KC HRW Wheat'、 'Rough Rice'、 'Soybean Oil'、 'Soybean'が含まれています。'ticker'と'commodity'は同じデータですので、'ticker'は削除します。'open'は市場のオープニング価格、'close'は終了時の価格、'high'は最高価格、'oow'は最低価格です。'volume'は取引数です。どの列にも欠損値はありません。'date'は年月日ですがデータタイプがobject(文字列)になっていますので時系列型に変換します。
表の頭から5行を表示

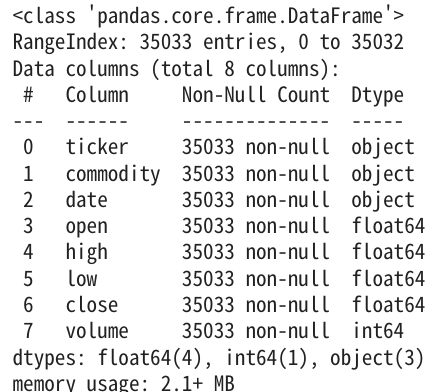
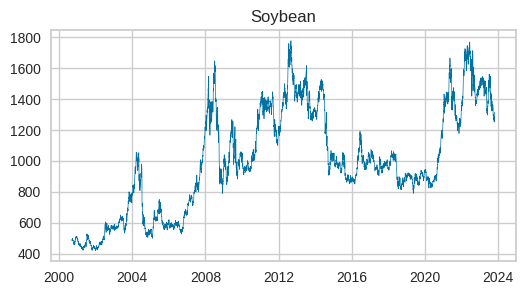
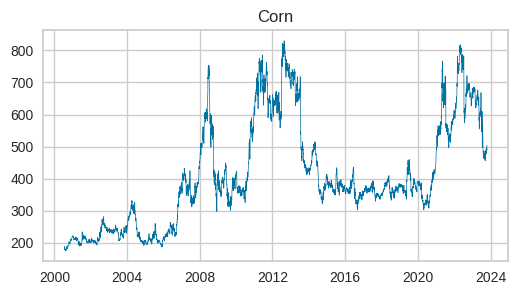
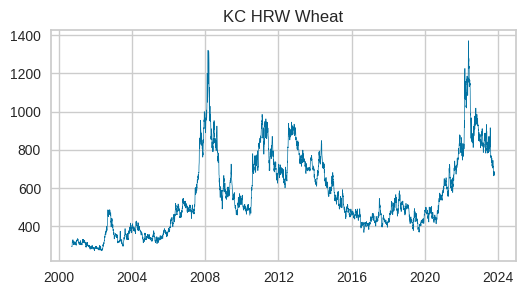
open priceデータの時系列推移を可視化
時系列データは、周期的な変動、トレンド的な変動、その他の突発的な変動に分けて分析するのが基本です。
各グラフを一見すると、大豆、トウモロコシ、小麦の動きは非常に良く似ています。大豆がやや上昇傾向が強いようです。2020年には米がピークを迎え、他の作物にはありません。ベトナムが米の輸出枠を設定したためだそうです。
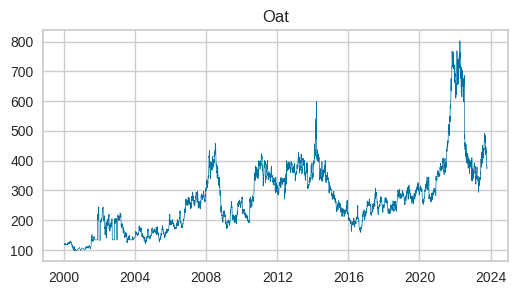
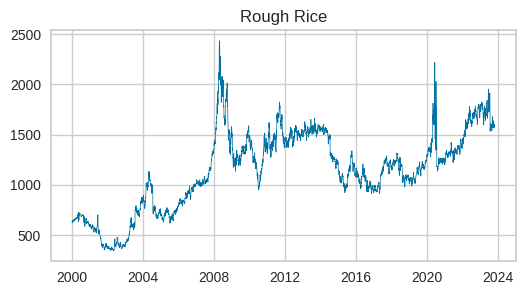
ちなみに試験運用中の生成AIのGoogle検索体験SGE(Google Search Generative Experience)(かなり便利です)で穀物の価格上昇について聞いてみたところ、以下のサイトがヒットしました。上図価格変動要因の推測に参考になります。
Pycaretによる価格予測のための機械学習モデルの作成
pythonによる機械学習モデルの作成ではライブラリscikit-learnが良く使われていますが、今回はローコード(基本的には2行のコード)で説明変数の前処理(欠損値の対応、カテゴリー変数のone-hot encoding、クロスバリデーションなど)と網羅的に多くのモデル(回帰では19モデル)を作成してくれるライブラリPycaretを用いました。
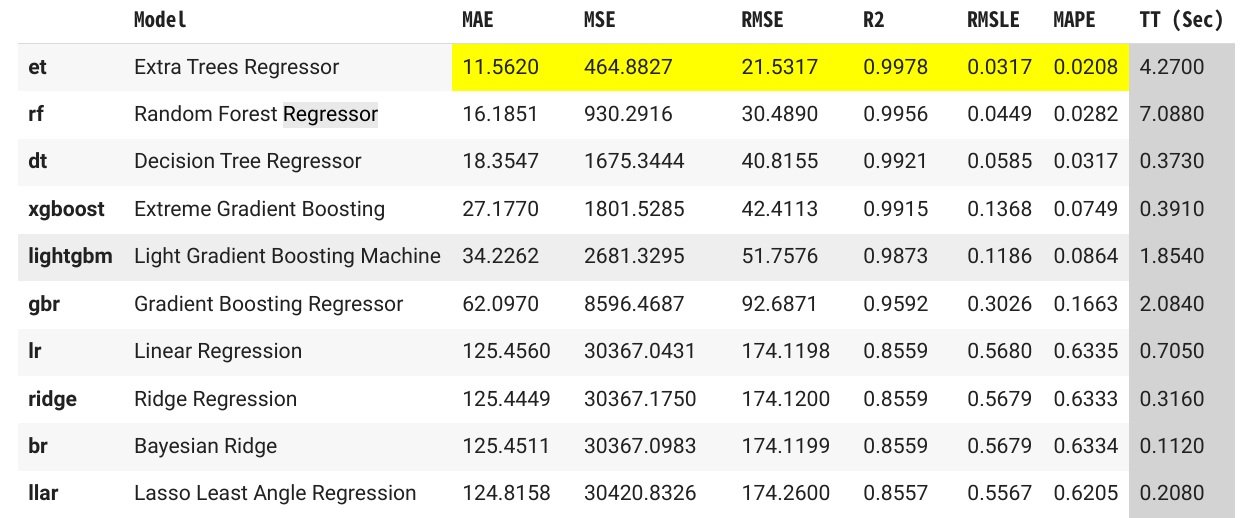
作成された精度上位の10モデルを下表に示します。
6種の指標全てでExtra Trees Regressorがトップになりました。Pycaretでは、デフォルトのパラメータで作成されていますので、トップ3ぐらいのモデルに絞り込んでパラメータのチューニングをすることができます。
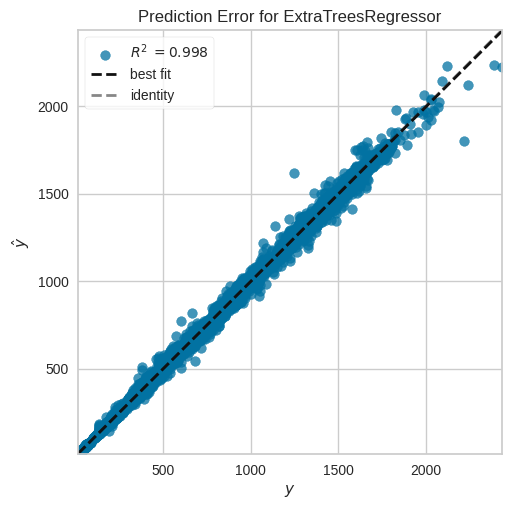
Prediction Error for Extra Trees Regressor model
Feature Importance Plot for Extra Trees Regressor model
Feature Importance は、機械学習モデルの解釈に使用される指標です。各特徴量がターゲットにどれだけ影響を与えたかを表し、モデルが重要視している要因を知ることができます。Feature Importance は、ジニ不純度(Gini impurity)に基づいて計算されます。具体的には、ある特徴量で分割することでどれくらいジニ不純度を下げられるのかを評価するそうです。
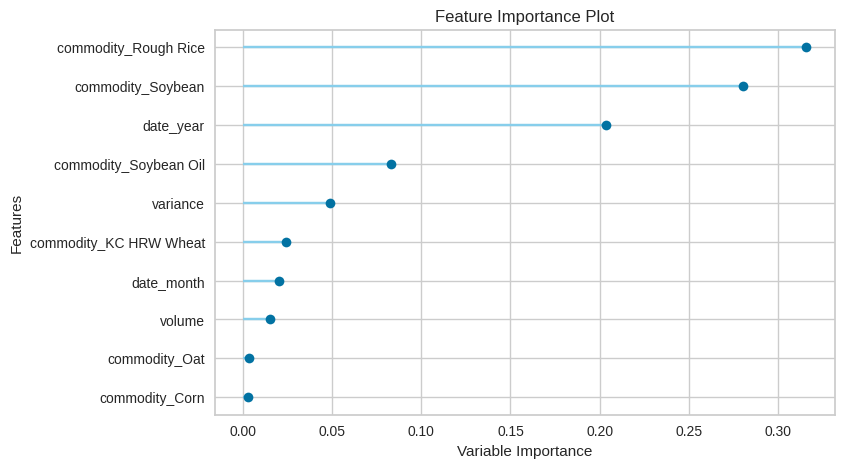
R^2=0.9987であり、Exta Trees Regressorは、作物の種類と日付を考慮することで、open priceに対して非常に優れたモデル予測を提供すると言うことができます。
このモデルにとってより重要なパラメータは、作物の種類と年であり、月はある程度の情報を提供するが、日はあまり重要ではないようです。
Pythonによるプログラムのコード
実際に解析に用いたプログラムのコードです。あくまで参考です。自己責任で適当に編集して試してください。
開発・実行環境:Google Colaboratory
ダウンロードしたzipファイルの解凍
datasetのあるサイトページからダウンロードするとzipファイルでダウンロードされますので、解凍します。unzipフォルダに解凍されたcsvファイルが保存されます。
# Import
import zipfile
# unpack
filename = 'archive.zip'
with zipfile.ZipFile(filename) as zf:
f_list = zf.namelist()
with zipfile.ZipFile(file) as zf:
for fcsv in f_list:
zf.extract(fcsv, 'unzip')
install
!pip install pycaret # ローコードで機械モデルを作成
import
from pycaret.regression import *
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
データの読み込みと抽出
# データの読み込み
df = pd.read_csv("all_grains_data.csv")
# 列'date'を時系列データに変換
df['date'] = pd.to_datetime(df['date'], format'%Y-%m-%d')
print(df.shape) # 列数と行数を表示
print(df.info()) # 各列の情報を表示
print(df.head()) # 表を頭から5行表示
列'open'の穀物別時系列推移の可視化
# plot関数の定義
def openplot(type):
crop = df[df['commodity']==type]
plt.figure(figsize(6,3))
plt.plot(crop['date'], crop['open'], c='b', lw=0.5)
plt.title(type)
openplot('Soybean')
openplot('Corn')
openplot('KC HRW Wheat')
openplot('Oat')
openplot('Rough Rice')
Pycaretによるopen price予測のための機械学習モデルの作成
# 不要な列の削除
word_df = df.drop(columns=['ticker', 'high', 'low', 'close'])
# Pycaretによるデータの前処理
s = setup(word_df, target='open', session_id=123)
# Pycaretによる機械学習モデルの作成・比較
best = compare_models()
Extra Trees Regessor model の予測誤差plot
plot_model(best, plot='error')
Feature Importance Plot
plot_model(best, plot='feature')